Method
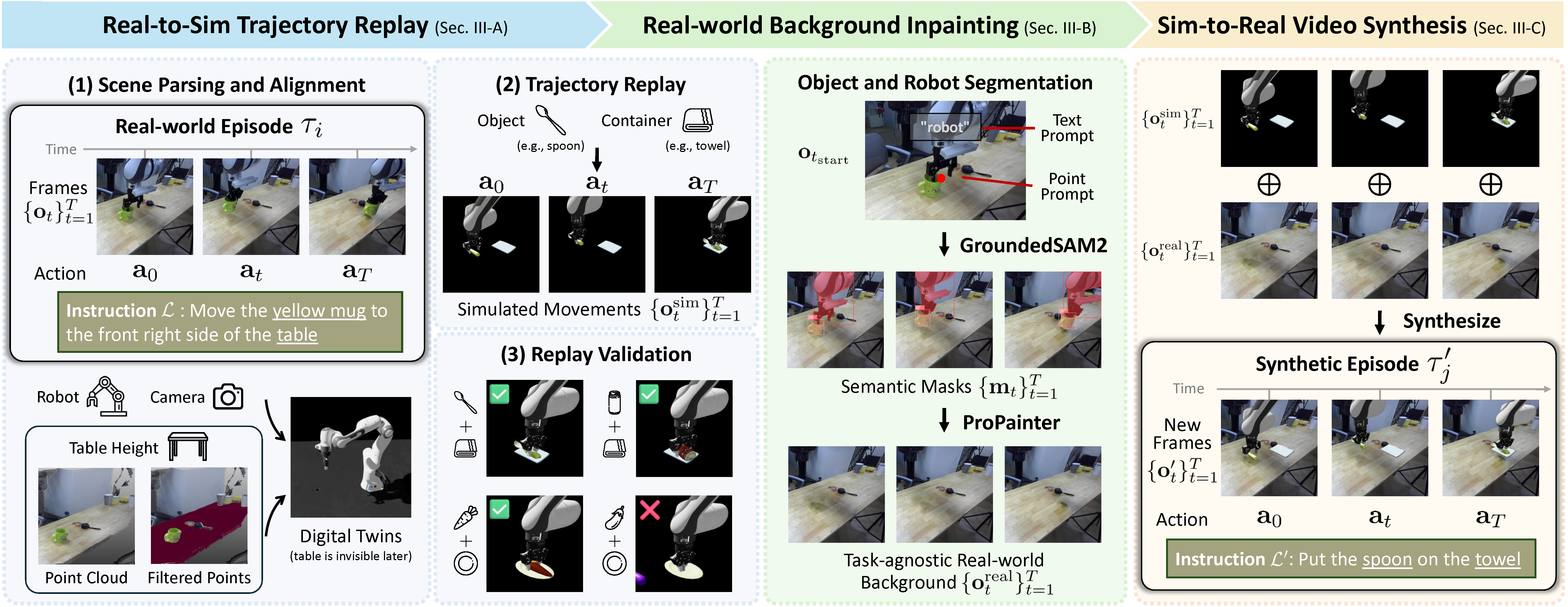
ReBot includes three key components:
- Real-to-Sim Trajectory Replay. For each real-world episode, we automatically set up digital twins in a simulation environment, and replay the real-world robot trajectory to obtain simulated movements for manipulating new objects. We validate the scalability of our approach by demonstrating that real-world trajectories can be successfully reused to manipulate different shapes of objects in simulation.
- Real-world Background Inpainting. To obtain task-agnostic real-world background for video synthesis, we introduce an automated inpainting module with GroundedSAM2 to segment and track the robot and object (i.e., task-specific elements) in original real-world videos, and remove them with ProPainter.
- Sim-to-Real Video Synthesis. We eventually integrate simulated movements with task-agnostic real-world background, producing synthetic videos with realistic physics and excellent temporal consistency.